파이썬 : 크롤링 - 카페 영업시간, 전화번호 데이터 수집
파이썬 Crawling을 도와주는 모듈은 크게 1. Selenium 2. BeatifulSoup가 있다.
Selenium : 웹브라우저를 띄우고 우리가 키보드 마우스로 하는 동작들을 자동화해주는 역할을 수행한다.
BeatifulSoup : 정적인 HTML과 XML 문서를 parsing 하기 위한 패키지로 html에서 데이터를 추출하는데 사용한다.
Chrome Web Driver : ChromeDriver는 Selenium WebDriver가 Chrome과 상호 작용하는 데 사용하는 또 다른 실행 파일입니다. Chrome 웹 브라우저에서 작업을 자동화하려면 ChromeDriver도 설치해야 합니다.
Selenium 관련 메서드
.get() : 특정 웹사이트로 이동하기 위해 url 값을 파라미터 값으로 넣어 해당 url로 이동한다.
.click() : element 클릭
.find_element() : class, id, css, xpath 등으로 요소 찾기
BeatifulSoup 관련 메서드
BeautifulSoup(html,"html.parser") : HTML 파일을 BeautifulSoup 객체로 제공해준다. "html.parer" 는 분석 타입을 제공하는 것으로 HTML 분석 타입이다. 별도로 제공하지 않을 시 디폴트값으로 HTML 타입이 제공된다.
find() : HTML 태그를 추출하는 메소드로 HTML 태그 한 개를 반환한다.
find_all() : HTML 태그를 추출하는 메소드로 HTML 태그 여러 개를 담고 있는 리스트를 반환한다.
get_text() : BeautifulSoup 객체에 get_text()를 적용하면 태그에서 텍스트를 반환한다.
네이버 플레이스에서 카페이름을 키워드로 검색하여 해당 카페 영업시간 데이터와 전화번호 데이터를 수집해야하는 예이다.
1) URL 검색
"https://m.place.naver.com/place/list?query="+ {카페이름} + "&level=top"
browser.get("https://m.place.naver.com/place/list?query="+ query + "&level=top")
time.sleep(3)
soup = BeautifulSoup(browser.page_source, 'html.parser')
1) 네이버 플레이스 화면 이동
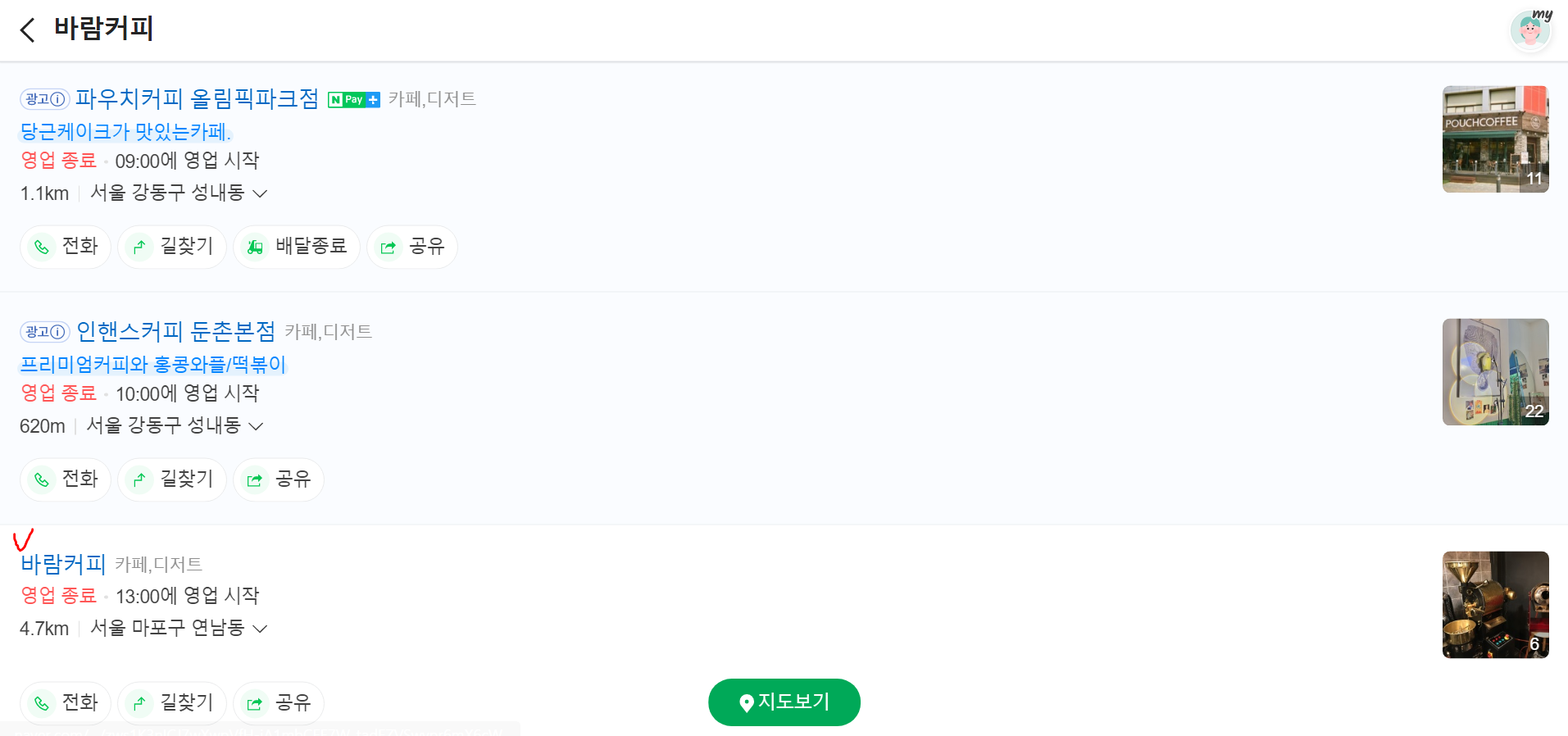
2) 검색 결과 카페 리스트를 대상으로 반복문을 돌며 검색 카페 이름과 같은 카페명을 가진 블럭을 찾기
3) selenium 라이브러리가 지원하는 clik() 메서드를 이용해 카페 상세화면으로 이동
loop_cnt = 1;
for store in store_list:
if(store.get_text() == query):
try:
# 검색 결과가 다중일 경우
browser.find_element(By.XPATH, '//*[@id="_list_scroll_container"]/div/div/div[2]/ul/li['+str(loop_cnt)+']/div[2]/a[1]/div/div/span[1]').click()
except:
# 검색결과가 단일일 경우
browser.find_element(By.XPATH, '//*[@id="_list_scroll_container"]/div/div/div[2]/ul/li/div[1]').click()
break
loop_cnt += 1
else:
print("검색 카페가 존재하지 않음 : ", query)
not_exist.append(query)
continue
4) 요일별 영업시간을 보기 위해 영업시간 데이터 블럭을 클릭하여 펼치기.
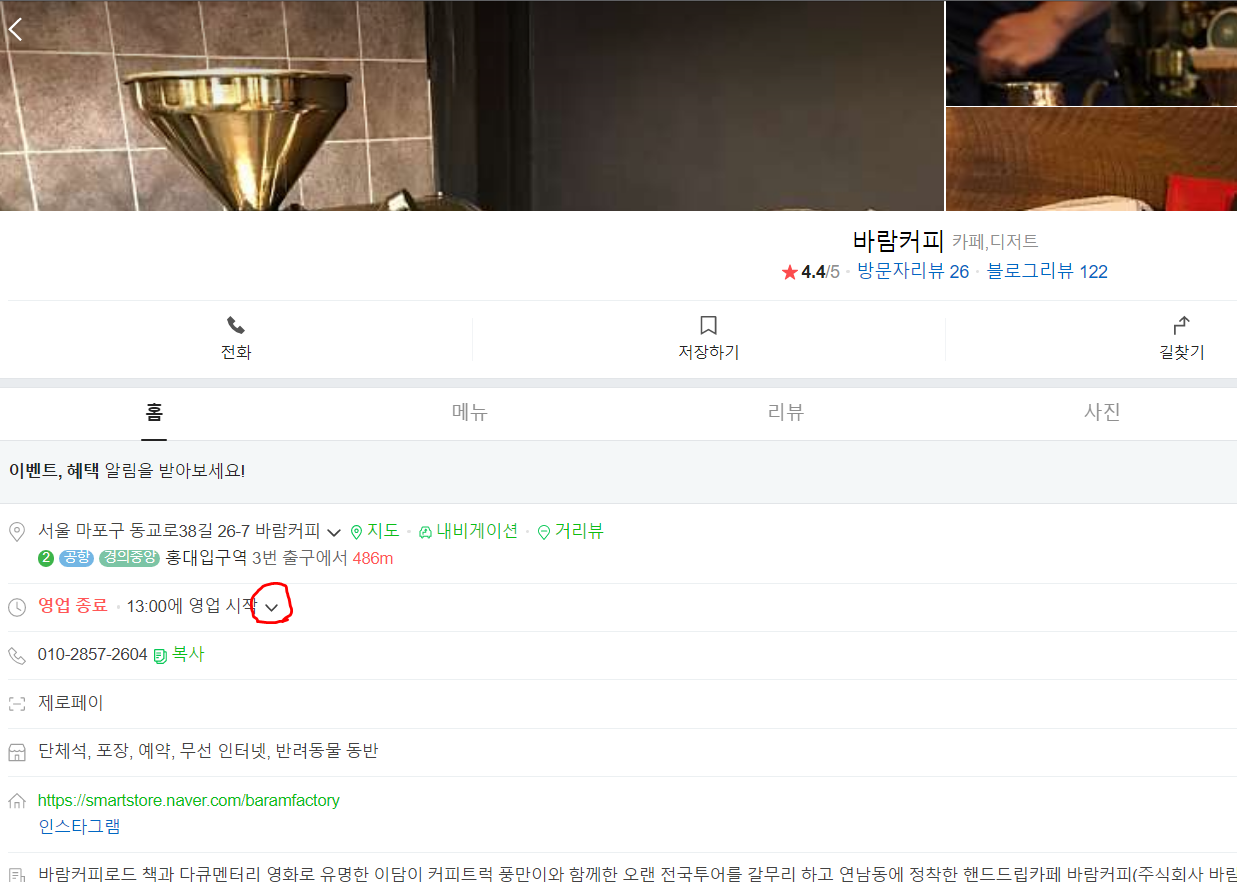
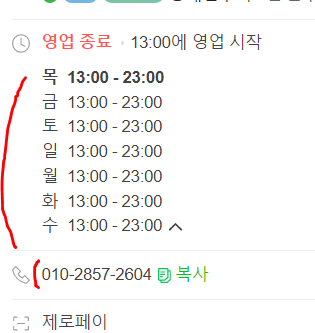
5) 이제 카페 상세 화면에 요일별 수집할 영업시간 데이터, 전화번호 데이터가 모두 출력되기 때문에 해당 HTML 코드를 찾아가 본인의 애플리케이션 데이터 포맷에 맞게 딕셔너리 or 리스트 타입으로 데이터를 저장하면 된다.
-ex) 영업시간 데이터 저장 코드 일부
open_time = split_time[0][0:5]
closed_time = split_time[1][0:5]
#요일별 영업시간 딕셔너리 생성
business_hour_dict = {'open':open_time, 'closed':closed_time}
if(day_text == '월'):
store_dict['businessHours']['onMon'] = business_hour_dict
elif(day_text == '화'):
store_dict['businessHours']['onTue'] = business_hour_dict
elif(day_text == '수'):
store_dict['businessHours']['onWed'] = business_hour_dict
elif(day_text == '목'):
store_dict['businessHours']['onThu'] = business_hour_dict
elif(day_text == '금'):
store_dict['businessHours']['onFri'] = business_hour_dict
elif(day_text == '토'):
store_dict['businessHours']['onSat'] = business_hour_dict
elif(day_text == '일'):
store_dict['businessHours']['onSun'] = business_hour_dict
elif(day_text == '매일'):
store_dict['businessHours']['onMon'] = business_hour_dict
store_dict['businessHours']['onTue'] = business_hour_dict
store_dict['businessHours']['onWed'] = business_hour_dict
store_dict['businessHours']['onThu'] = business_hour_dict
store_dict['businessHours']['onFri'] = business_hour_dict
store_dict['businessHours']['onSat'] = business_hour_dict
store_dict['businessHours']['onSun'] = business_hour_dict
break
json_list.append(store_dict)
6) 저장한 데이터를 로컬에 JSON 파일로 저장한다.
def toJson(json_list):
with open('store_info_data.json', 'w', encoding='utf-8') as file :
json.dump(json_list, file, ensure_ascii=False, indent='\t')